
上一篇我们提到了HBase的安装和基本操作,这一节我们将介绍一下HBaseJavaAPI的使用。
我们知道Hbase是存储于HDFS之上的,在rootDir这里可以查看到其路径
s2:50070/ 浏览文件系统可以查看到hbase这个目录,点进去可以看到两个内置的名称空间 default和hbase。

创建Maven项目 HbaseDemo.
配置pom:
1 |
|
创建APP执行类 编写程序
这里是进行建表操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23//创建HBase配置对象 返回Hadoop的配置
public static void main(String[] args) throws Exception, ZooKeeperConnectionException, IOException {
Configuration config = HBaseConfiguration.create();
System.out.println("Create Table Begin~~");
//创建一个HBase管理员 client包下的
HBaseAdmin admin = new HBaseAdmin(config);
//管理员封装了很多方法
//构建表名对象 org.apache.hadoop.hbase.TableName 注意包别导错
TableName tn = TableName.valueOf("t_wyc_apicreate");
//HTableDescriptor 表描述符 建表的话需要这个参数 这里输入表名和设置列族
HTableDescriptor tdes = new HTableDescriptor(tn);
//添加列族 这里需要HColumnDescriptor 列描述对象
HColumnDescriptor column = new HColumnDescriptor("data");
tdes.addFamily(column);
//表描述符传入创建表的方法
admin.createTable(tdes);
System.out.println("Create Table Over~~");
}
导出export成jar包
运行程序
export HBASE_CLASSPATH=xxx.jar 设置一个HBase的ClassPath变量为指定jar包
hbase ClassName 直接运行其jar文件即可
quanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ export HBASE_CLASSPATH=HBaseDemo1.jarquanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ hbase com.wyc.hbase.HBaseApp
打印日志如下:1
2
3
4
5
6Create Table Begin~~
2017-09-16 03:07:11,537 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
SLF4J: C
。。。。。
2017-09-16 03:07:21,451 INFO [main] client.HBaseAdmin: Created t_wyc_apicreate
Create Table Over~~
查看表是否创建
quanquan@s2:/mnt/hgfs/shareDownload/hbaseDemo$ hbase shellhbase(main):001:0> list1
2
3TABLE
t_wyc_apicreate
1 row(s) in 0.6010 seconds
代表表创建OK。
编程式CURD 操作HBase
这里我们代码如下(鼠标可拖动代码块):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144package com.wyc.hbase;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
/**
* 测试HBase CURD操作
Bytes为hadoop的工具类
* @author 圈圈
* @version 1.0
*/
public class TestCURD {
//这里执行建表和插入数据操作
public static void main(String[] args) throws Exception {
//创建HBase配置对象 返回Hadoop的配置
Configuration config = HBaseConfiguration.create();
//建表 上文有提到过
HBaseApp.createTable("curd_demo", "data");
System.out.println("Create Table Begin~~");
//构建HTable对象
HTable table = new HTable(config, "curd_demo");
System.out.println("准备往表 curd_demo 插入3条数据");
//这里展示CURD的方法 org.apache.hadoop.hbase.util.Bytes 采用工具类的这个Bytes方法
//构建Put插入数据对象 传入参数为行键
Put put = new Put(Bytes.toBytes("row1"));
//插入数据 指定列族以及列名
put.addColumn(Bytes.toBytes("data"), Bytes.toBytes("a"), Bytes.toBytes("wycInsert1"));
put.addColumn(Bytes.toBytes("data"), Bytes.toBytes("b"), Bytes.toBytes("wycInsert2"));
put.addColumn(Bytes.toBytes("data"), Bytes.toBytes("c"), Bytes.toBytes("wycInsert3"));
//封装对象 将该对象插入表中 可以Put一个List集合 批量插入
table.put(put);
System.out.println("插入成功 即将查询:");
//查询采用Get对象 条件查询
List<String> column_list = new ArrayList<String>();
//封装要查询的列名
column_list.add("a");
column_list.add("b");
//调用查询方法
System.out.println("开始查询");
search(table,"row1","data",column_list);
System.out.println("查询结束");
//scan扫描 查询
System.out.println("开始扫描");
scan(table);
System.out.println("结束扫描");
System.out.println("删除开始");
//删除操作
//同理也是需要删除对象(可以传入行键)
Delete delete = new Delete(Bytes.toBytes("row1"));
//加列族限制条件
delete.addColumn(Bytes.toBytes("data"), Bytes.toBytes("a"));
table.delete(delete);
System.out.println("删除结束");
//查询采用Get对象 条件查询
//调用查询方法
System.out.println("删除后开始查询");
search(table,"row1","data",column_list);
System.out.println("删除后查询结束");
//删除表 drop之前要先禁用 禁用就涉及到了管理员对象
HBaseAdmin admin = new HBaseAdmin(config);
System.out.println("禁止表开始");
admin.disableTable("curd_demo");
System.out.println("禁止表结束");
System.out.println("删除表开始");
admin.deleteTable("curd_demo");
System.out.println("删除表结束");
if( table != null ) table.close();
if( admin != null ) admin.close();
}
/**
* 根据查询条件查询 HBase的表
* @param table 表对象
* @param rowKey 行键
* @param columnFamily 列族
* @param columnName 列名集合
* @throws Exception
*/
("deprecation")
public static void search(HTable table,String rowKey,String columnFamily,List<String> columnName) throws Exception{
//查询采用Get对象
Get get = new Get(Bytes.toBytes(rowKey));
//如果这里不想查询整行数据 可以添加列族 或者添加列族加列
//这里封装查询条件 查询2列数据
if(!columnName.isEmpty()){
for(int i =0;i<columnName.size();i++){
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName.get(i)));
}
}
//获取返回结果
Result result = table.get(get);
result.getRow();
List<KeyValue> list = result.list();
list.stream().forEach((x)->System.out.println("data.key="+Bytes.toString(x.getKey())
+" data.value="+Bytes.toString(x.getValue())));
}
/**
* 全表扫描
* @throws Exception
*/
public static void scan(HTable table) throws Exception {
//scan方法 全表扫描 可以传入get对象封装扫描条件
Scan scan = new Scan();
//getScanner 返回 ResultScanner
ResultScanner resultScanner = table.getScanner(scan);
//获取迭代器迭代对象
Iterator<Result> it = resultScanner.iterator();
while(it.hasNext()){
Result r = it.next();
System.out.println(Bytes.toString(r.getRow())+"="
+Bytes.toString(r.getColumnLatest(Bytes.toBytes("data"), Bytes.toBytes("a")).getValue()));
}
}
}
这时候我们打开主机查看:
export后并执行: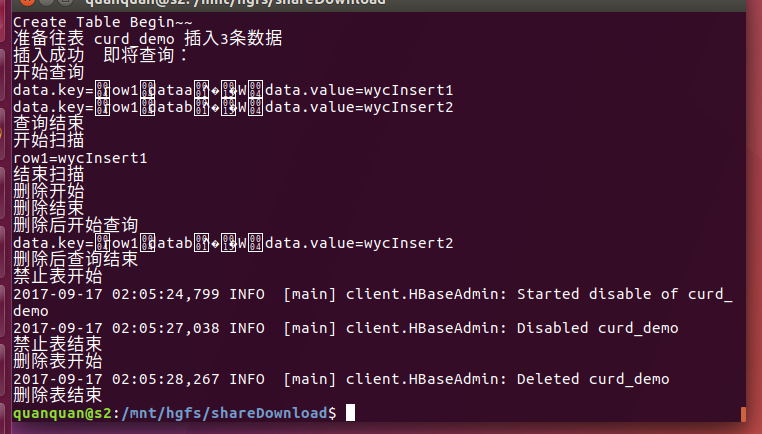
代表执行OK。
刚刚表最后也删除了,查询不到了,修改操作实际上就是Put到指定行键、列族、列集的操作,put某一个cell的数据后来的时间戳为最新的,HBase默认显示最新时间戳的数据。
HBase新型API
我们知道我们之前使用的很多方法要么有改动或者有bug被标记为deprecated,例如HBaseAdmin我们进到HBaseAdmin中 JavaDoc 可以看到 HBase不再是一个客户端API,它被标注为InterfaceAudience注解,使用Connection.getAdmin()方法直接构造新型实例。链接对象应该由ConnectionFactory.createConnection(Configuration)获得。
不过时的新型API代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132package com.wyc.hbase.newapi;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Objects;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
/**
* HBase 新型API
* 测试执行类
* @author 圈圈
* @version 1.0
*/
public class HbaseNewApiApp {
public static void main(String[] args) {
Connection createConnection = null;
Admin admin =null;
Table table =null;
try {
//获取HBase配置对象
Configuration conf = HBaseConfiguration.create();
//获取一个连接实例
createConnection = ConnectionFactory.createConnection(conf);
//获取Admin对象
admin = createConnection.getAdmin();
//deleteTable 如果表存在就删除否则接下来创建
deleteTable(admin);
//必须添加一个表名
HTableDescriptor desc = new HTableDescriptor( TableName.valueOf("f_newapi_wyc"));
//必须指定一个列族
HColumnDescriptor colu = new HColumnDescriptor(Bytes.toBytes("courses"));
desc.addFamily(colu);
//管理员建表操作
admin.createTable(desc);
//取得这张表
table = createConnection.getTable(TableName.valueOf("f_newapi_wyc"));
Put put = new Put(Bytes.toBytes("row1"));
//添加列族和列名以及值 (cell内容)
put.addColumn(Bytes.toBytes("courses"), Bytes.toBytes("English"), Bytes.toBytes("97"));
put.addColumn(Bytes.toBytes("courses"), Bytes.toBytes("Math"), Bytes.toBytes("57"));
put.addColumn(Bytes.toBytes("courses"), Bytes.toBytes("Chinese"), Bytes.toBytes("87"));
//插入数据
table.put(put);
System.out.println("插入row1的3条数据成功~");
//查询数据
ResultScanner scanner = table.getScanner(Bytes.toBytes("courses"));
//新型API遍历其结果集
for (Result result : scanner) {
//每一个存储单位称之为一个cell
List<Cell> cells = result.listCells();
for(Cell c: cells){
String family = Bytes.toString(CellUtil.cloneFamily(c));
String column_name = Bytes.toString(CellUtil.cloneQualifier(c));
String value = Bytes.toString(CellUtil.cloneValue(c));
System.out.println("family="+family+" columnName="+column_name+" value="+value);
}
}
System.out.println("查询完毕。即将开始大批量插入操作~");
//大批量操作
batch(table);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
if( table!=null )table.close();
if( admin!=null )admin.close();
if( createConnection!=null )createConnection.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
/**
* 批量插入HBase
* @param table
*/
public static void batch(Table table) throws Exception {
List<Put> put_list=new ArrayList<Put>();
//
Objects.requireNonNull(table,"表对象为空!");
for(int i=1;i<=50000;i++){
Put put = new Put(Bytes.toBytes(i));
put.addColumn(Bytes.toBytes("courses"), Bytes.toBytes("batch"+i), Bytes.toBytes("batch_value"+i));
put_list.add(put);
}
System.out.println("批量插入完毕");
table.put(put_list);
}
/**
* 删表操作
* @param admin 传入管理员对象
* @throws Exception
*/
public static void deleteTable(Admin admin) throws Exception{
Objects.requireNonNull(admin,"管理员对象为空!");
//判断表是否存在
if(admin.tableExists(TableName.valueOf("f_newapi_wyc"))){
admin.disableTable(TableName.valueOf("f_newapi_wyc"));
admin.deleteTable(TableName.valueOf("f_newapi_wyc"));
System.out.println("表删除成功");
}
}
}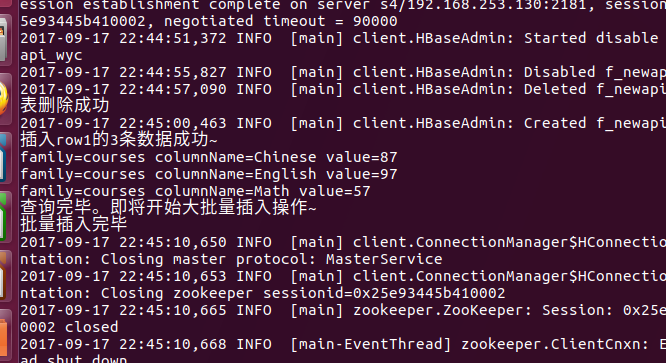
如上输出代表插入操作都ok 注意插入字符串流转换正常,基本类型会显示乱码。
HBase Shell 下的常用命令:
create 'tableName','columnFamily' 建表和列族put 'columnFamily','ColumnName','value' 插入指定数据get 'TableName','ColumnFamily'disable 'tableName' 禁用表drop 'tableName' 删除表list 查看表help [null or command] 查看全部帮助/指定命令帮助scan '[tableName]' 类似于select *describe同mysql一样,都是描述表信息与结构hbase(main):003:0> describe 'f_newapi_wyc'1
2
3
4
5
6
7
8Table f_newapi_wyc is ENABLED
f_newapi_wyc
COLUMN FAMILIES DESCRIPTION
{NAME => 'courses', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE =>
'65536', REPLICATION_SCOPE => '0'}
1 row(s) in 0.4300 seconds
count查询表中记录数hbase(main):004:0> count 'f_newapi_wyc'

统计完成 上面代码插入了50001条数据。count还可以携带参数 每5000显示一次 缓存1000条,查询速度更快:count 'tableName', INTERVAL=>5000,CACHE=>1000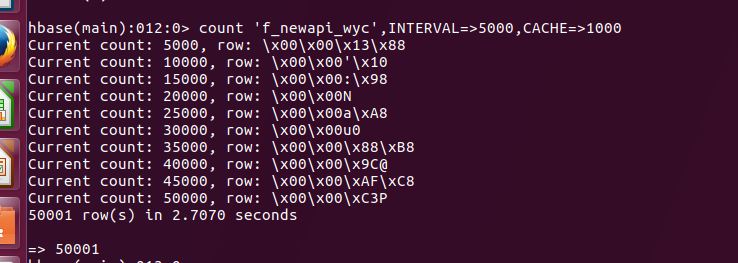
whoami 查询当前用户信息以及组信息。
Ubuntu终端进入zookeeper 客户端之下:
hbase zkcli hbase进入hbase zookeeper客户端
显示zookeeper各节点以及端口号,进入客户端模式。
如果配置了环境变量,使用 zkCli.sh -server s2:2181 可以进入环境变量模式。ls /ls /hbase
可以查看文件系统的目录以及文件信息,例如我们想查看RegionServer服务器信息,ls /hbase/rs
输出信息如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30[zk: s2:2181,s3:2181,s4:2181,s5:2181(CONNECTED) 2] ls /hbase/rs
[s5,16020,1505709288393, s3,16020,1505709287260, s4,16020,1505709289741]
·get 主机信息 或者指定的 备份节点信息 get 指令
get /hbase/master
[zk: s2:2181,s3:2181,s4:2181,s5:2181(CONNECTED) 3] get /hbase/master
�master:16000+�����PBUF
s2�}��+�}
cZxid = 0x100000012
ctime = Sun Sep 17 21:34:58 PDT 2017
mZxid = 0x100000012
mtime = Sun Sep 17 21:34:58 PDT 2017
pZxid = 0x100000012
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x15e93445b760002
dataLength = 50
numChildren = 0
ls /hbase/table/ 可以查看具有哪些表存在
ZookeeperCLI界面可以查看一些表的元数据信息,(get )
·help命令可以查看到许多分组以及具体指令,例如名称空间的:
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
hbase(main):002:0> list_namespace
list_namespace list_namespace_tables
hbase(main):002:0> list_namespace
NAMESPACE
default
hbase
2 row(s) in 0.8090 seconds
可以看到2条HBase带的default默认的名称空间以及hbase的名称空间,hbase目录下有我们新建的表。
查看指定名称空间下的指定表:hbase(main):004:0> scan 'hbase:namespace'
输出信息如下:1
2
3
4
5
6ROW COLUMN+CELL
default column=info:d, timestamp=1505709313635, value=\x0A\x07defa
ult
hbase column=info:d, timestamp=1505709314483, value=\x0A\x05hbas
e
2 row(s) in 0.4230 seconds
限制条件查询:
查询1-10条的数据:hbase(main):011:0> scan 'f_newapi_wyc',LIMIT=>10
输出信息如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22ROW COLUMN+CELL
\x00\x00\x00\x01 column=courses:batch1, timestamp=1505713503277, value=batc
h_value1
\x00\x00\x00\x02 column=courses:batch2, timestamp=1505713503277, value=batc
h_value2
\x00\x00\x00\x03 column=courses:batch3, timestamp=1505713503277, value=batc
h_value3
\x00\x00\x00\x04 column=courses:batch4, timestamp=1505713503277, value=batc
h_value4
\x00\x00\x00\x05 column=courses:batch5, timestamp=1505713503277, value=batc
h_value5
\x00\x00\x00\x06 column=courses:batch6, timestamp=1505713503277, value=batc
h_value6
\x00\x00\x00\x07 column=courses:batch7, timestamp=1505713503277, value=batc
h_value7
\x00\x00\x00\x08 column=courses:batch8, timestamp=1505713503277, value=batc
h_value8
\x00\x00\x00\x09 column=courses:batch9, timestamp=1505713503277, value=batc
h_value9
\x00\x00\x00\x0A column=courses:batch10, timestamp=1505713503277, value=bat
ch_value10
10 row(s) in 0.2300 seconds
本节我们介绍了HBaseJava API操作以及HBase的基本shell命令,下一届将HBase表拆分等相关操作。